问题背景:
今天发现hx01 redis6379节点频繁报耗时过高。
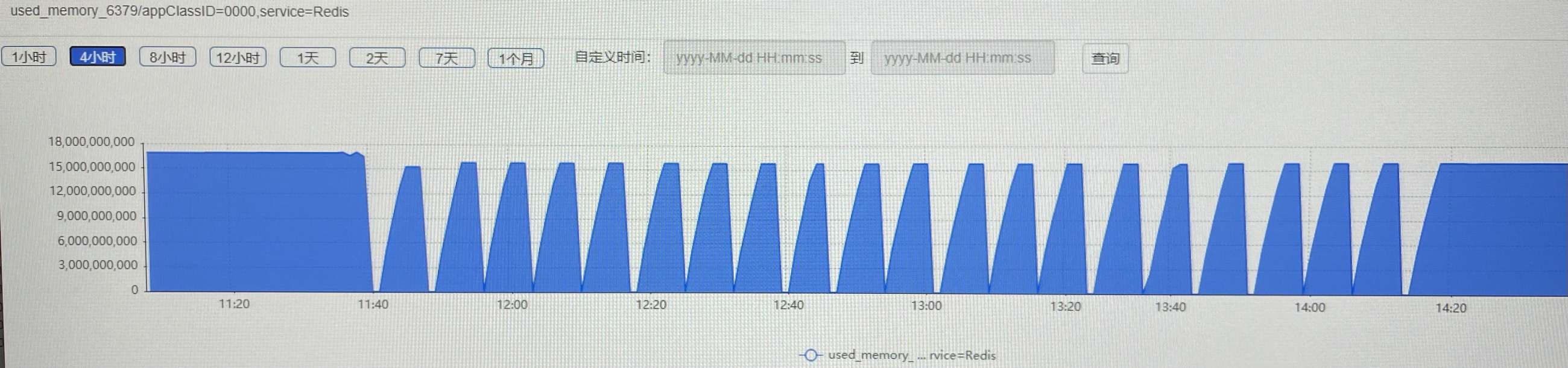
进入环境发现6379服务为从节点,top查看发现频繁内存增加释放,且cpu占用100%。这明显是不对的,有问题
尝试通过清cache没用
sync; echo 3 > /proc/sys/vm/drop_caches
这要通过redis日志查看具体原因了。
打开logfile
./redis-cli -p 6379
>config set logfile /data/redislog/redis.log
查看日志发现:
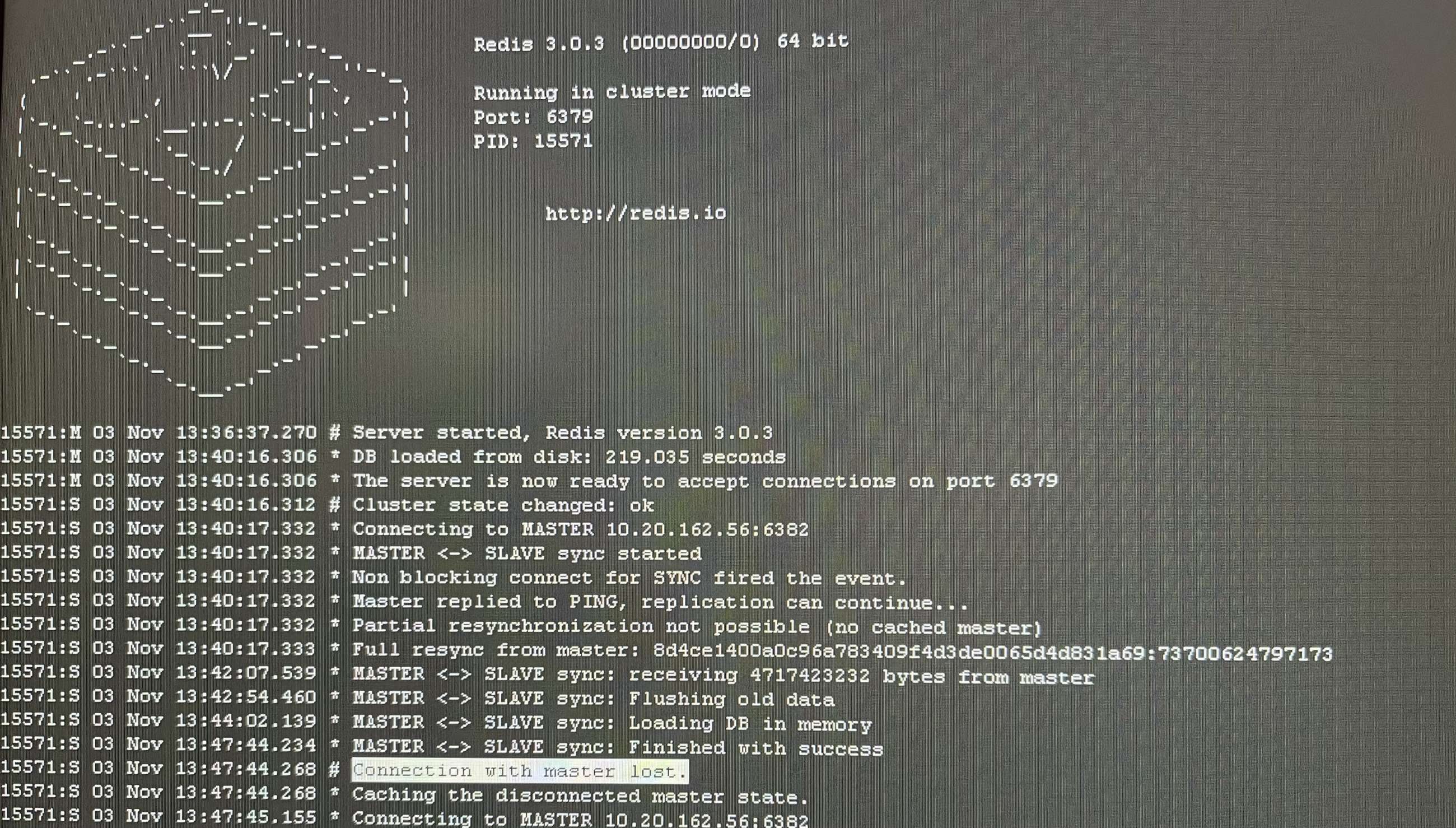
6379节点会频繁发主从同步请求,因为,报了Connection with master lost.错误
那这个原因,主要是由于redis主节点配置
client-output-buffer-limit slave配置的值过小了。(主节点通过psync做部分同步,在部分同步时由于client-output-buffer-limit slave值设置的太小导致数据发送失败,失败后,从节点继续发起数据同步请求)
查看6379对应主节点redis.conf配置发现配置为:
client-output-buffer-limit slave 1024mb 512mb 120
意思是最大output-buffer限制为1024m,output-buffer缓冲区持续120s内不超过512m。
通过config get client-output-buffer-limit查看也可知
127.0.0.1:6382>config get client*
1) "client-output-buffer-limit"
2)"normal 0 0 0 slave 1073741824 536870912 120 pubsub 33554432 8388608 60"
那么将其设置为不限制
client-output-buffer-limit slave 0 0 0
或通过redis-cli连接再 config set在该6379服务设置也可:
config set client-output-buffer-limit "slave 0 0 0"
这样就可以正常主从同步了,如第一张图14.20后就正常了。
参考:
redis重做从库时报Connection with master lost错误
其实,根本原因还是,主机内存太小了,80G内存,4个节点每个节点
maxmemory 16gb
另外,将修改的配置保存到配置文件方法:
config rewrite
redis主从同步时报Connection with master lost.:等您坐沙发呢!