glusterfs 做remove-brick迁移导致内存爆掉。
对glusterfs集群主机扩内存。
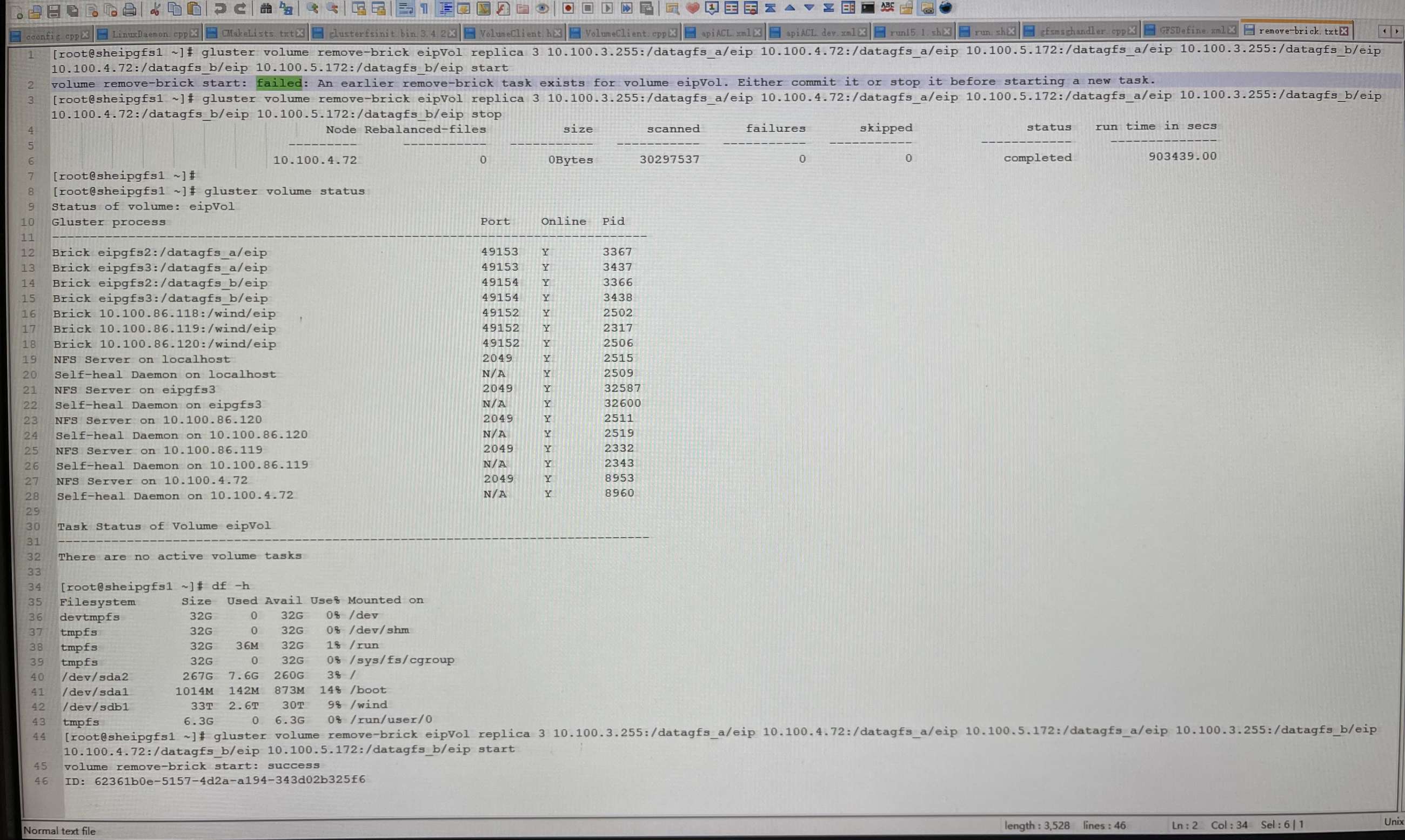
操作步骤时,么有对remove-brick做stop操作。
直接关机扩内存,重启。
然后查看要修复的文件:gluster volume heal eipVol info
扩内存重启后,查看remove-brick status时发现竟然变为comlpele状态。但任务状态还在。
因为前面没有对remove-brick做stop操作(应该在关机扩内存前做remove-brick stop操作)。当再次重启remove-brick时,发现启动失败。
需要对remove-brick做stop操作后。再次start启动缩brick迁移数据。
另外,今天查看日志/var/log/glsuterfs/etc-glusterfs-glusterd.vol.log发现有:
Failed to get handshake ack from remote server的错误..
而且发现gluster peer status有个节点disconnect了。
把glusterfs进程kill掉后,重启起不起来了...
启动报错,报找不到rdma.so..这是什么鬼..
排查发现:
/var/lib/glusterd/peers目录下,有几个节点信息变为空了!!!
因为没有节点地址信息,导致启动glusterd服务失败。
从其他节点对应的配置文件中得到对应节点信息,并修复这几个空文件。
重启成功。
20230921
glusterfs集群172.17.1.11节点挂掉重启glsuterd服务起不来。
查看日志发现

连接其他节点有问题。
将所有gluster进程kill掉。
重启glusterd。
service glusterd start
service glusterd status
查看解决。
20231115
glusterfs集群(172.18.1.35-37)迁移重启后
172.18.1.35节点的RawData卷进程glusterfsd进程起不来了。
查看3个节点peers对应的节点信息发现:

172.18.1.36的节点信息被莫名改了。。
删除掉hostname2=172.18.1.35
重启glusterd。
service glusterd start
启动RawData卷
gluster volume start RawData
查看集群status
gluster volume status
恢复正常。
20240821
glusterfs日志文件占用空间太大。删除日志文件,杀掉glusterfs进去,重启glusterfs服务起不起来了。
通过debug模式启动
/usr/sbin/glusterd -f /etc/glusterfs/glusterd.vol -p /var/run/glusterd.pid --log-level DEBUG --log-file /var/log/glusterfs/1111.log
查看日志发现:
连接netglusterfs05(172.18.1.15)报错了,导致启动服务失败。
查看/var/lib/glusterd/peers目录,发现竟然没有了netglusterfs05的配置了。将这个节点配置文件加上,重启成功。
glusterfs 做remove-brick迁移导致内存爆掉遇到的一系列问题及解决:等您坐沙发呢!